Connecting ChatGPT with your own Data using Llama Index and LangChain
In the last three months, there has been a rapid increase in the use of Large Language Models (LLMs) for a variety of applications, such as creating AI-generated songs like Drake’s “Tootsie Slide”, Chat GBT’s customer service chatbots, and Prompt Agent GPT’s impressive natural language processing capabilities.
In this blog post, I will investigate the use of LangChain and LlamaIndex, two innovative tools that offer standardization and interoperability. I will discuss the main uses of each, how they are similar, and how one might be more suitable for your needs. It is important to note that these libraries are still in their early stages and are being improved on a regular basis, so some of the information provided may not be accurate depending on when you read it.
What is LLM?
LLMs are machine learning models that use statistical patterns to generate text that is similar to human language and can respond to prompts in a natural way. They are trained on large amounts of data, such as books, articles, and websites, in order to predict the most likely words or phrases to come after a given input.
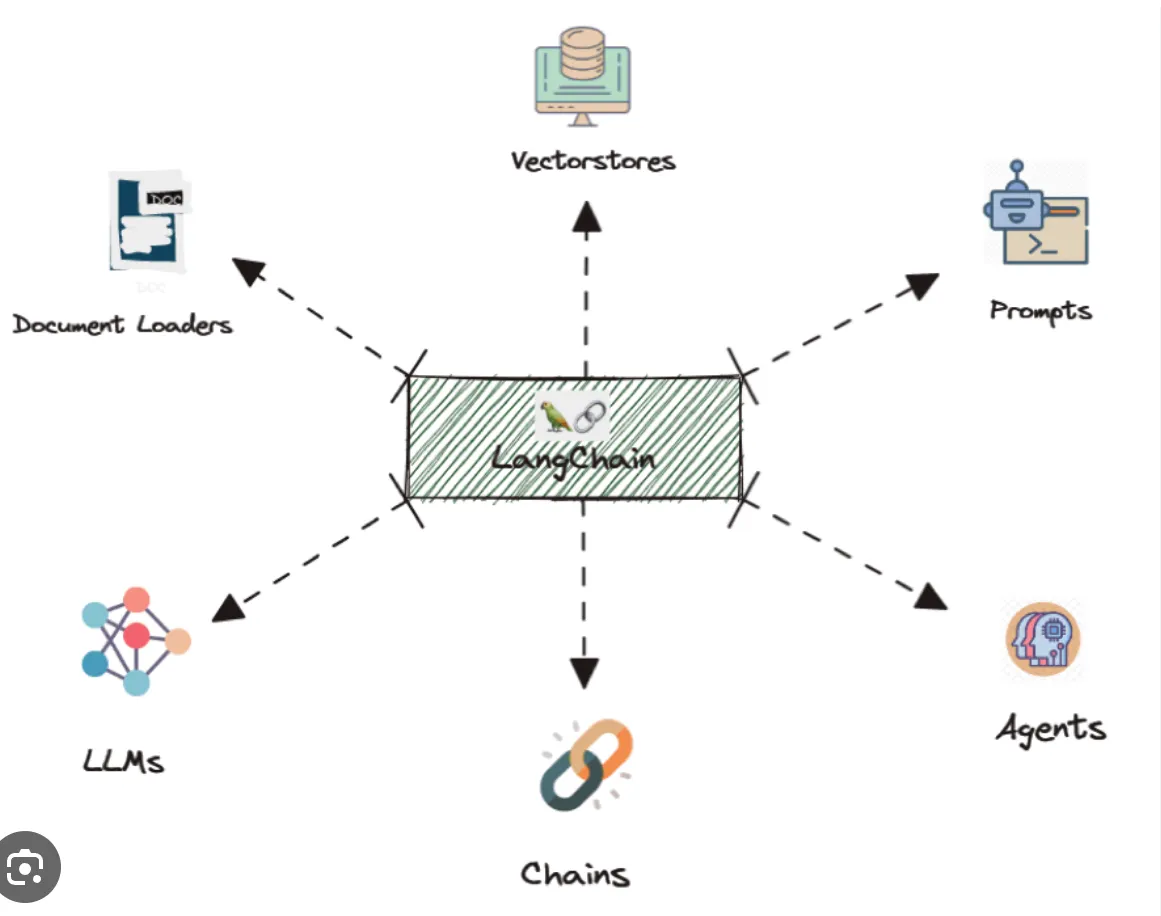
LangChain — Standardizing Interactions
The complexity of LLMs, with their frequent updates and large number of parameters, has created intense competition among providers. To simplify the process of utilizing these models, Huggingface and Cohere have developed APIs that abstract away many of the challenges associated with cloning code, downloading trained weights, and manually configuring settings. However, some use cases still require tailored prompts, and not all APIs offer the same features, leading to a need for standardized interactions and interoperability so that users can switch between providers without being locked in to one vendor.
LLama Index
The figure below illustrates the overall workflow of a Llama index:

A strategy is needed to feed large documents into LLMs in a way that is efficient and uninterrupted. To achieve this, the knowledge base (e.g., organizational docs) is divided into smaller pieces and each piece is stored in a node object, which together form a graph (index) with other nodes. This chunking of the knowledge base is necessary due to the limited input token capacity of LLMs, allowing for a smoother and more continuous input of documents.
We can create individual list indexes for different sources, such as Confluence, Google Docs, and emails, and then combine them into a hierarchical tree index. This will help us to better organize documents and improve search results by creating an overarching tree index from the individual list indexes.
Let’s get more granular and find out how the documents are chunked up. LangChain provides a set of textSplitter classes that are designed to break up input to a language model in order to stay within token limitations for LLMs. The textSplitter can split by the number of characters, number of tokens, or other costume measurements. Since these chunks are to be sequentially fed to an LLM, there is some overlap between them to maintain context. LlamaIndex uses these textSplitter classes to chunk the docs. However, if we need control over how our documents are chunked, custom splitters can be created or a simpler approach would be to create our chunks beforehand and use those to create nodes of a graph index. This is possible because, in LlamaIndex, a graph can be created from either a set of documents or a set of nodes.
Let's get into a real-world example:
Support you are asked to use ChatGPT model with companies own data specifically for summarization perspective.
Below is the step by step solution
- Data Loading
PDFReader = download_loader("PDFReader")
loader = PDFReader()
plans = os.listdir("data")
doc_titles = [plan.split('.')[0] for plan in plans]
docs = {}
for doc in doc_titles:
docs[plan]= loader.load_data(file=Path(f"data/{doc}.pdf"))2. Plug and play any LLM. I am using gpt-3.5–turbo for this article.
llm_predictor_gpt35 = LLMPredictor(llm=ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo"))
service_context = ServiceContext.from_defaults(
llm_predictor=llm_predictor_gpt35,
chunk_size_limit=500
)3. Vectorizing your own data. For this article I am using my own resume in pdf doc format.
vector_indices = {}
for doc in plan_titles:
vector_indices[doc] = GPTVectorStoreIndex.from_documents(
plan_docs[doc], service_context=service_context
)
vector_indices[doc].index_struct.index_id = plan
vector_indices[doc].storage_context.persist(persist_dir=f"index_{plan}.json")I am saving the vectorized output to minimize chatgpt cost.

4. Loading the vectorized output I saved in step 3.
for doc in plan_titles:
storage_context[plan] = StorageContext.from_defaults(
docstore=SimpleDocumentStore.from_persist_dir(persist_dir=f"index_{doc}.json"),
vector_store=SimpleVectorStore.from_persist_dir(persist_dir=f"index_{doc}.json"),
index_store=SimpleIndexStore.from_persist_dir(persist_dir=f"index_{doc}.json"),
graph_store=SimpleGraphStore.from_persist_dir(persist_dir=f"index_{doc}.json"),
)
vector_indices = {}
for plan in plan_titles:
vector_indices[plan] = load_index_from_storage(storage_context[plan])5. Creating an SimpleGPTKeywordTable index on top of embedding vectors
index_summaries = {}
for plan in plan_titles:
index_summaries[plan]= (
f"This is content specific to {plan} plan."
f"Use this index if you need to lookup specific facts about {plan} .\n"
)
graph = ComposableGraph.from_indices(
GPTSimpleKeywordTableIndex,
[index for _, index in vector_indices.items()],
[summary for _, summary in index_summaries.items()],
max_keywords_per_chunk=50
)6. Lastly Creating a treeindex on top of SimpleGPTKeywordTable index to have branch nodes representing each document for faster query retrieval and document summarization.
num_children = len(vector_indices) + 1
outer_graph = ComposableGraph.from_indices(
GPTTreeIndex,
[index for _,index in vector_indices.items()] + [root_index],
[summary for _,summary in index_summaries.items()] + [root_summary],
num_children=num_children
)7. Using as_query_engine to prompt our own data along with chatgpt
content = input("")
query_engine = outer_graph.as_query_engine()
response = query_engine.query(content)
print(response)Final Output

LangChain vs LlamaIndex
As you can tell, LlamaIndex has a lot of overlap with LangChain for its main selling points, i.e. data augmented summarization and question answering. LangChain is imported quite often in many modules, for example when splitting up documents into chunks. You can use data loaders and data connectors from both to access your documents.
LangChain offers more granular control and covers a wider variety of use cases. However, one great advantage of LlamaIndex is the ability to create hierarchical indexes. Managing indexes as your corpora grows in size becomes tricky and having a streamlined logical way to segment and combine individual indexes over a variety of data sources proves very helpful.
Overall these two helpful libraries are very new and are receiving updates weekly or monthly. I would not be surprised if LangChain subsumed LlamaIndex in the near future to offer a consolidated source for all applications.
